

Blueprint Developer Manual / Version 2010
Table Of ContentsRequirements
Technical editors should be able to adjust site behavior regarding robots (also known as crawlers or spiders) from search engines like Google. For example:
Enable/disable crawling of certain pages including their sub pages.
Enable/disable crawling of certain single documents.
Specify certain bots to crawl different sections of the site.
To support this functionality most robots follow the rules of robots.txt
files like explained here:
http://www.robotstxt.org/.
For example, the site "Corporate" is accessible as
http://corporate.blueprint.coremedia.com. For all content of this site the robots
will look for a file called robots.txt by performing an HTTP GET request to
http://corporate.blueprint.coremedia.com/robots.txt.
A sample
robots.txt file may look like this:
User-agent: Googlebot,Bingbot
Disallow: /folder1/
Allow: /folder1/myfile.html
Example 5.2. A robots.txt file
Solution
Blueprint's cae-base-lib module provides a
RobotsHandler which is responsible for generating a robots.txt
file. A RobotsHandler instance is configured in blueprint-handlers.xml.
It handles URLs like
http://corporate.blueprint7.coremedia.com:49080/blueprint/servlet/service/robots/corporate
This is a typical preview URL. In order to have the correct external URL for the robots one
needs to use Apache rewrite URLs that forwards incoming GET requests for
http://corporate.blueprint7.coremedia.com/robots.txt to
http://corporate.blueprint7.coremedia.com:49080/blueprint/servlet/service/robots/corporate
The RobotsHandler will be responsible for requests like this due to the
path element /robots The last path element of this URL (in this example
/corporate will be evaluated by RobotsHandler to determine
the root page that has been requested. In this example "corporate" is the URL segment of the
Corporate Root Page. Thus, RobotsHandler will use Corporate root page's
settings to check for Robots.txt configuration.
To add configuration for a Robots.txt file the corresponding root page
(here: "Corporate") needs a setting called Robots.txt
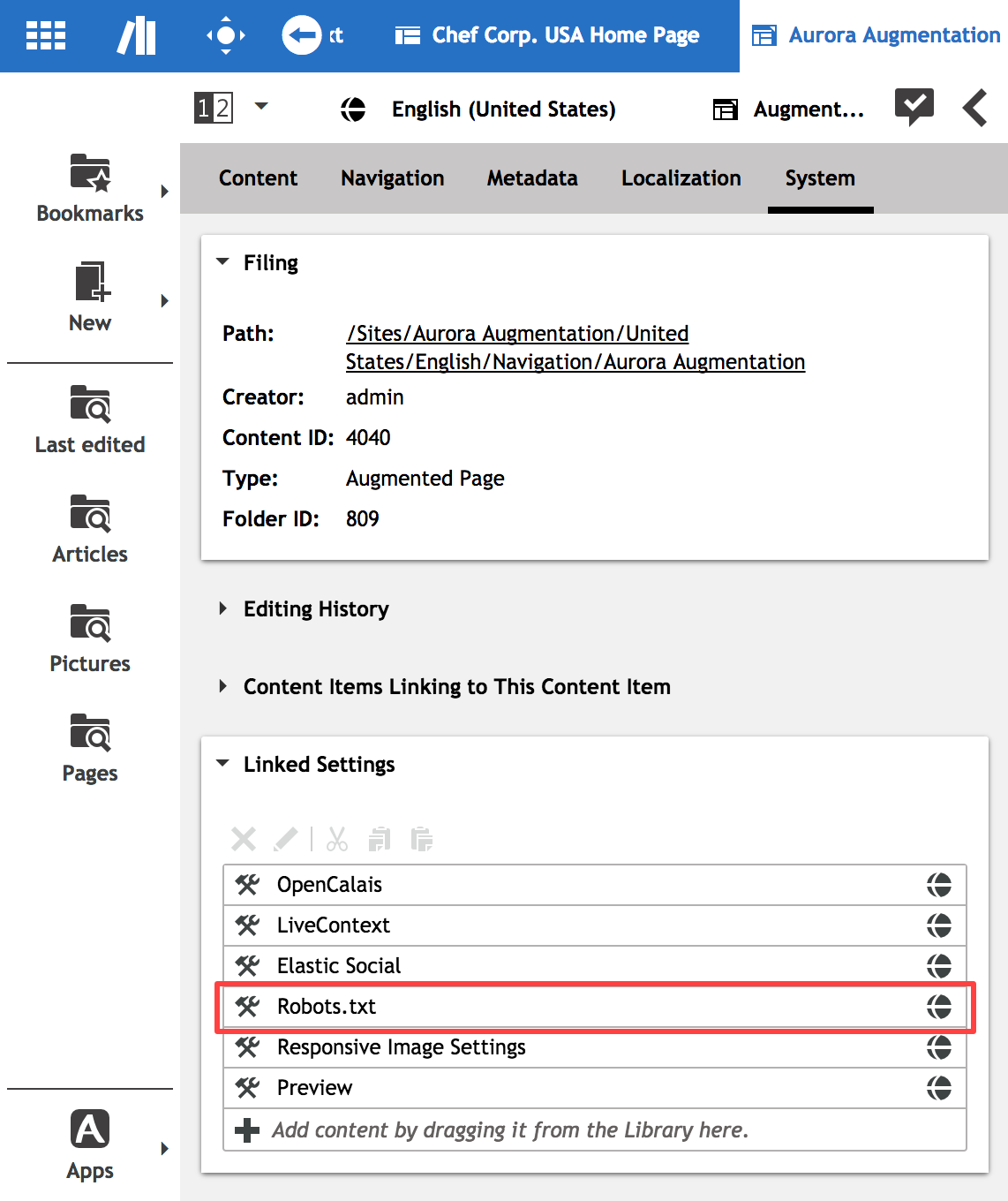
Example configuration for a Robots.txt file
The settings document itself is organized as a StructList property like in this
example:
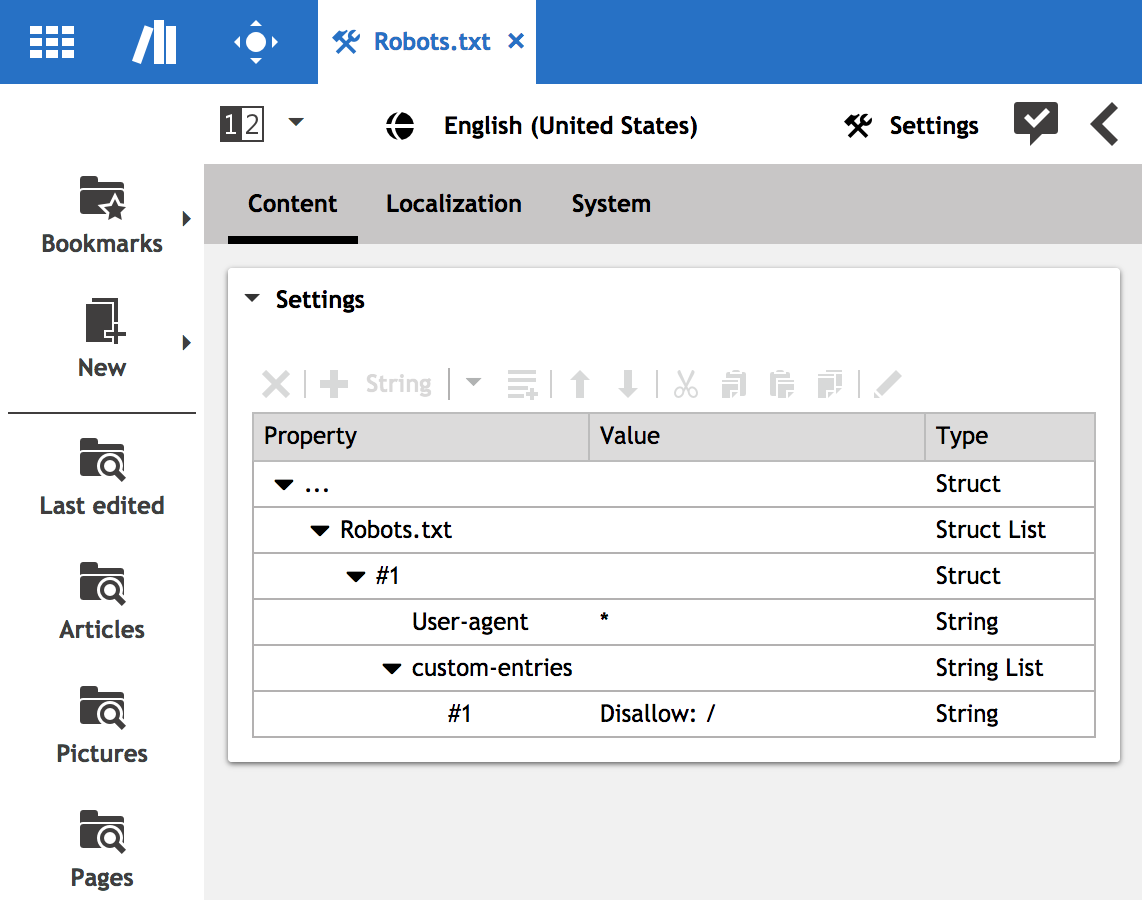
For any specified user agent the following properties are supported:
User-agent: Specifies the user agent(s) that are valid for this node.Disallow: A link list of items to be disallowed for robots. This list specifies a black list for navigation elements or content: Elements that should not be crawled. Navigation elements will be interpreted by "do not crawl elements below this navigation path". This leads to two entries in the resultingrobots.txtfile: one for the link to the navigation element and one for the same link with a trailing '/'. The latter informs the crawler to treat this link as path (thus the crawler will not work on any elements below this path). Single content elements will be interpreted as "do not crawl this document"Allow: A link list of items to be explicitly allowed for robots. This list specifies navigation elements or content that should be crawled. It is interpreted as a white list. Usually one would only use a black list. However, if you intend to hide a certain navigation path for robots but you want one single document below this navigation to be crawled you would add the navigation path to the disallow list and the single document to the allow list.custom-entries: This is a String List to specify custom entries in theRobots.txt. All elements here will be added as a new line in theRobots.txtfor this node.
The example settings document will result in the following robots.txt file:
User-agent: *
Disallow: /corporate/corporate-information/
Allow: /corporate/corporate-information/contact-us
User-agent: Googlebot
Disallow: /corporate/embedding-test
Example 5.3. robots.txt file generated by the example settings