Solution Overview for Business Users / Version 2506.0
Table Of ContentsRequirements
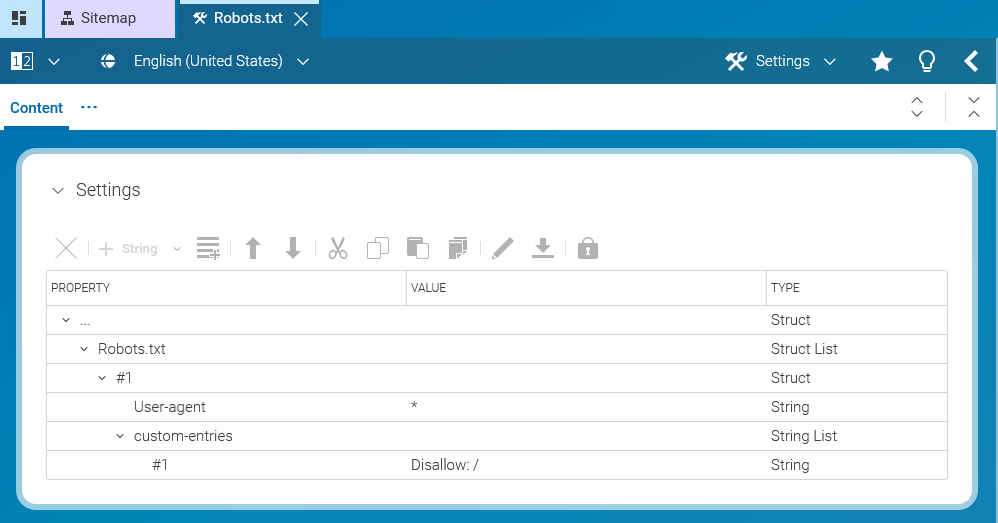
Technical editors should be able to adjust site behavior regarding robots (also known as crawlers or spiders) from search engines like Google. For example:
Enable/disable crawling of certain pages including their sub pages.
Enable/disable crawling of certain single content items.
Specify certain bots to crawl different sections of the site.
To support this functionality most robots follow the rules of robots.txt
files like explained here:
http://www.robotstxt.org/.
For example, the site "Corporate" is accessible as
http://corporate.blueprint.coremedia.com. For all content of this site the robots
will look for a file called robots.txt by performing an HTTP GET request to
http://corporate.blueprint.coremedia.com/robots.txt.
Solution
The so called RobotsHandler will be responsible for requests like this due to the path element /robots. The last path element of this URL (in this example /corporate will be evaluated by RobotsHandler to determine the root page that has been requested.
In this example "corporate" is the URL segment of the Corporate Root Page.